Streamlining Medical Record Briefs: Utilize AWS Transcribe and LangChain
Welcome to the slightly quirky tutorial on how to automate medical record briefs with LangChain and AWS. We’ll make sure even the most sacred HIPAA gods are pleased with our efforts to keep things confidential!
Overview
Objective: Turn those long, boring patient-doctor chats into neat, tidy, and compliant medical record briefs for scientists to do further research without breaking a sweat (or a law).
Tools Used: AWS Transcribe (because who can type that fast?) and LangChain (the HIPAA whisperer).
Compliance: Stick to HIPAA like glue, ensuring no personal info slips through.
Step 1: Record the Conversation
Grab that recording device and catch every “uhm” and “aah” in the consultation room. Just remember:
Requirements
Employ a high-quality microphone (older tech like a 2009 flip phone won’t suffice).
Get a thumbs up for recording from everyone involved. It’s HIPAA 101!
Step 2: Upload the Audio to AWS
Got the audio? Great! Now let’s send it to the cloud. But as a responsible digital citizen, I’ve never actually recorded any of my doctor’s visits. So, for this tutorial, we’ll use a dummy conversation from YouTube instead. Here’s how you can view it:
Instructions
Enter the AWS realm with your login credentials.
Pick a bucket on AWS S3. It’s like choosing a planter for your digital flowers.
Upload the chit-chat and let AWS do its heavy lifting.
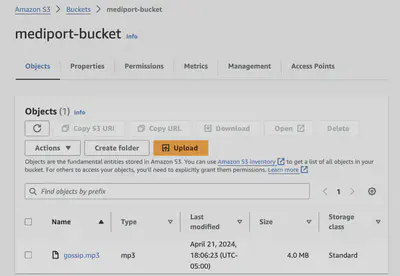
So here I have a bucket named mediport-bucket , and I already have a chichat recording uploaded in the bucket.
Figure: AWS S3 Bucket Created For Storing the Recording and I have uploaded the audio file gossip.mp3 to it.
If you really trust your ear and think you can do better than AWS, I will provide you with the audio file Chit-Chat in a doctor’s office..
Step 3: Transcribe Audio with AWS Transcribe
It’s time to turn those spoken words into written magic.
Steps
Find AWS Transcribe and pretend you know what all the buttons do.
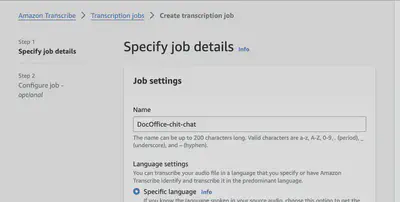
Create a transcription job:
Choose your gossip file from the S3 bucket.
Set the language (Well, AWS supports translating doctor-speak into plain English, but here since we already know what language we are using, we will just use English).
In this step, you can also enable a few more optional features like PII (Personally Identifiable Information) redaction, speaker identification, etc. But for now, we will keep it simple and use LangChain to redact the PII.(Otherwise, there would be no need for LangChain, right?)
Figure: AWS Transcribe Job Created For Transcribing Doctor-Patient Chit-Chat
Let it rip and wait for the text to appear.
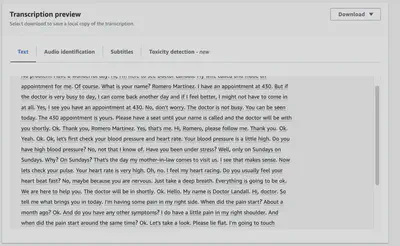
Tada! The transcription is ready. You can download it in JSON, TXT, or SRT format. Or, you can even use API request to retrive the transcription. Below is a screenshot of the transcription in plain text format.
Figure: Transcribed Conversation
Grab your transcription—it’s like fishing, but you actually catch something. Since we are going to use LangChain, it will be better if we can use API to automate the process. Below is the code snippet to get the transcription link using boto3. And then we can use this link to get the transcription text.
importboto3importtime# Create a client to interact with AWS Transcribetranscribe=boto3.client('transcribe')# Configuration for the transcription jobjob_name="DocOffice-chit-chat-copy"job_uri="s3://mediport-bucket/gossip.mp3"defstart_transcription_job():response=transcribe.start_transcription_job(TranscriptionJobName=job_name,LanguageCode='en-US',MediaSampleRateHertz=44100,MediaFormat='mp3',Media={'MediaFileUri':job_uri})returnresponsedefcheck_job_status(job_name):response=transcribe.get_transcription_job(TranscriptionJobName=job_name)returnresponse['TranscriptionJob']['TranscriptionJobStatus']defmain():print("Starting transcription job...")start_transcription_job()whileTrue:status=check_job_status(job_name)print("Current job status:",status)ifstatusin['COMPLETED','FAILED']:breaktime.sleep(5)# Wait for 5 seconds before checking the job status againifstatus=='COMPLETED':print("Transcription completed successfully.")result=transcribe.get_transcription_job(TranscriptionJobName=job_name)print("Transcription URL:",result['TranscriptionJob']['Transcript']['TranscriptFileUri'])else:print("Transcription job failed.")if__name__=="__main__":main()
So the output of the above code will be the transcription URL. We can use this URL to get the transcription text. Here I will just attach the transcription text for the chit-chat recording. Since the output is in json format, I will just attach the text part of the json file.
{"jobName":"DocOffice-chit-chat-copy","accountId":"502795161362","status":"COMPLETED","results":{"transcripts":[{"transcript":"No problem. Have a wonderful day. Hi, I'm here to see Doctor Landall. My wife called and made an appointment for me..."}],"items":[{"type":"pronunciation","alternatives":[{"confidence":"0.996","content":"No"}],"start_time":"0.009","end_time":"0.119"},{"type":"punctuation","alternatives":[{"confidence":"0.0","content":"."}]}]}}
Since the original transcription is like a mile long, I have just attached the first few lines of the transcription.
Why is this output transcription so long? Well, it’s because the transcription is in JSON format. But don’t worry, we will use LangChain to redact the PII and make it more readable.
Step 4: Redact Confidential Information with LangChain
Let’s play hide and seek with personal information.
Setup
Get LangChain up and running.
Setting up LangChain is as easy as pie. Just follow the instructions on the website.
You can use pip install langchain to install LangChain.
You can also use docker to run LangChain. You can have easily set up langchain environment without messing with your local Python Libraries.
As for the benefits of using Container, let the data convince you. Here is a link to the Statistics about Container Technology provided by Statisca.
Don’t look at me, I don’t have any data to provide you with because I obviously don’t want to violate Statisca’s ToS. I am pretty sure Statisca knows me more than I do to myself, right?
For Statisca: Do you actually have to charge that amount of money just for a few statistics? I mean, I can just google it, right?
Prep your coding space. Coffee, anyone?
Redaction Process
Load the transcript into LangChain’s magic box.
First, you would load the transcript into the LangChain environment. This might be done via an API call, reading from a file, or through direct input.
fromlangchain_experimental.data_anonymizerimportPresidioAnonymizeranonymizer=PresidioAnonymizer()anonymizer.anonymize("My name is Slim Shady, call me at 313-666-7440 or email me at real.slim.shady@gmail.com")
The output of the above code will be:
'My name is Eric Miranda, call me at 359-509-8361x63389 or email me at michael77@example.org'
Wow, that’s so cool, right? You can be anyone, I can be anyone. We can all be anyone. If anyone’s personal information is leaked, we can just say, “It’s not me, it’s Eric Miranda.”
Awesome, now let’s define the rules for redacting the sensitive information from our transcription. But here we will not using fake names to make life more difficult for researchers, we will just redact the sensitive information but keep the must-have information.
frompresidio_analyzerimportPattern,PatternRecognizer# For Patient Namespatient_name_pattern=Pattern(name="patient_name_pattern",regex=r"\b[A-Z][a-z]+ [A-Z][a-z]+",# Simplified name patternscore=0.7)# For Patient DOBs, capturing dates and redacting all but the yearpatient_dob_pattern=Pattern(name="patient_dob_pattern",regex=r"(\d{1,2}[/-]\d{1,2}[/-])(\d{4})",# Assumes format DD/MM/YYYY or DD-MM-YYYYscore=0.8)# For Patient Emailspatient_email_pattern=Pattern(name="patient_email_pattern",regex=r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b",score=0.85)# For Patient Phonepatient_phone_pattern=Pattern(name="patient_phone_pattern",regex=r"(\+?\d{1,3}[ -]?)?(\(?\d{2,3}\)?[ -]?)?\d{3}[ -]?\d{3}[ -]?\d{3,4}",score=0.85# Adjust the score based on testing and accuracy)# Recognizer for Patient Namespatient_name_recognizer=PatternRecognizer(supported_entity="[PT_NAME]",patterns=[patient_name_pattern])# Recognizer for Patient DOBs (redacts the date, keeps the year)patient_dob_recognizer=PatternRecognizer(supported_entity="[PT_DOB]",patterns=[patient_dob_pattern])# Recognizer for Patient Emailspatient_email_recognizer=PatternRecognizer(supported_entity="[PT_EMAIL]",patterns=[patient_email_pattern])# Recognizer for Patient numberspatient_phone_recognizer=PatternRecognizer(supported_entity="PT_PHONE",patterns=[patient_phone_pattern])importretoRedAct=conversation[0]##Before the steps below make sure that you have loaded the pageContent to data# Replace namestoRedAct=re.sub(patient_name_pattern.regex,"[NAME]",toRedAct)# Replace DOBs but keep the yeartoRedAct=re.sub(patient_dob_pattern.regex,r"[PT_DOB\2]",toRedAct)# Replace emailstoRedAct=re.sub(patient_email_pattern.regex,"[PT_EMAIL]",toRedAct)# Replace phonetoRedAct=re.sub(patient_phone_pattern.regex,"[PT_PHONE]",toRedAct)print(toRedAct)
Check your work. No peeking allowed, secrets!
Review the redacted output to ensure all sensitive information has been correctly and adequately anonymized. You might also need to adjust the context or anonymize additional details to ensure the redaction is comprehensive.
Output
Redacted Transcript: No problem. Have a wonderful day. Hi, I’m here to see [NAME]. My wife called and made an appointment for me. Of course. What is your name? [NAME]. I have an appointment at 430. But if the doctor is very busy to day, I can come back another day and if I feel better, I might not have to come in at all. Yes, I see you have an appointment at 430. No, don’t worry. The doctor is not busy. You can be seen today. The 430 appointment is yours. Please have a seat until your name is called and the doctor will be with you shortly. Ok. Thank you, [NAME]. Yes, that’s me. Hi, Romero, please follow me. Thank you. Ok. Yeah. Ok. Ok, let’s first check your blood pressure and heart rate. Your blood pressure is a little high. Do you have high blood pressure? No, not that I know of. Have you been under stress? Well, only on Sundays on Sundays. Why? [NAME]? That’s the day my mother-in-law comes to visit us. I see that makes sense. Now lets check your pulse. Your heart rate is very high. Oh, no. I feel my heart racing. Do you usually feel your heart beat fast? No, maybe because you are nervous. Just take a deep breath. Everything is going to be ok. We are here to help you. The doctor will be in shortly. Ok. Hello. My name is [NAME]. Hi, doctor. So tell me what brings you in today. I’m having some pain in my right side. When did the pain start? About a month ago? Ok. And do you have any other symptoms? I do have a little pain in my right shoulder. And when did the pain start around the same time? Ok. Let’s take a look. Please lie flat. I’m going to touch different areas of your side and you tell me if it hurts or not, ouch, it hurts. I didn’t touch your side yet. Oh, ok. Does this hurt? Not really. How about this? No, not really. And this ouch, ok. You can sit up. I’m going to refer you to a specialist, a gastroenterologist doctor. Oh, no. What’s wrong with me? I’m not sure. But it could be something with your gallbladder. However, once you go to the specialist, he will be able to help you further another doctor. Oh, man. Hi, I’m [NAME]. What’s going on, buddy?
Hooray, Now we have a working redacted transcription. Let’s chain it up with some templates and finalize the medical record brief by calling GPT-4 Model.
Step 5: Finalize the Medical Record Brief
Process:
Create a template for the medical record brief.
Fill in the blanks with the redacted transcript.
Add a touch of magic with GPT-4 to make it sound professional.
CHAIN THEM! and send it to GPT-4 for finalization.
Review the output and make any necessary adjustments.
Below is a code snippet to generate the medical record brief using GPT-4.
importgetpassimportosfromlangchain_openaiimportChatOpenAIfromlangchain_core.output_parsersimportStrOutputParserfromlangchain_core.promptsimportChatPromptTemplateos.environ["OPENAI_API_KEY"]=getpass.getpass()model=ChatOpenAI(model="gpt-4")prompt=ChatPromptTemplate.from_template("Here is a conversation transcript without indicating the name of the person who is talking and based on your best knowledge please try your best to seperate the conversation and based on the conversation write a brief summary about this visit for future research purpose: {conversation}")output_parser=StrOutputParser()chain=prompt|model|output_parserchain.invoke({"conversation":toRedAct})
How about let’s guess what the output of the above code will be? I am pretty sure it will be a medical record brief following the redacted transcription.
"Person A: No problem. Have a wonderful day. \nPerson B: Hi, I'm here to see [NAME]. My wife called and made an appointment for me. \nPerson A: Of course. What is your name? \nPerson B: [NAME]. I have an appointment at 430. But if the doctor is very busy to day, I can come back another day and if I feel better, I might not have to come in at all. \nPerson A: Yes, I see you have an appointment at 430. No, don't worry. The doctor is not busy. You can be seen today. The 430 appointment is yours. Please have a seat until your name is called and the doctor will be with you shortly. \nPerson B: Ok. Thank you, [NAME]. \nPerson A: Yes, that's me. Hi, Romero, please follow me. \nPerson B: Thank you. \nPerson C: Ok. Yeah. Ok. Ok, let's first check your blood pressure and heart rate. Your blood pressure is a little high. Do you have high blood pressure? \nPerson B: No, not that I know of. Have you been under stress?\nPerson B: Well, only on Sundays on Sundays. Why? [NAME]? That's the day my mother-in-law comes to visit us. \nPerson C: I see that makes sense. Now lets check your pulse. Your heart rate is very high. Oh, no. I feel my heart racing. Do you usually feel your heart beat fast? \nPerson B: No, maybe because you are nervous. Just take a deep breath. Everything is going to be ok. We are here to help you. The doctor will be in shortly. \nPerson D: Ok. Hello. My name is [NAME]. \nPerson B: Hi, doctor. So tell me what brings you in today. \nPerson B: I'm having some pain in my right side. When did the pain start? About a month ago? \nPerson D: Ok. And do you have any other symptoms? \nPerson B: I do have a little pain in my right shoulder. And when did the pain start around the same time? \nPerson D: Ok. Let's take a look. Please lie flat. I'm going to touch different areas of your side and you tell me if it hurts or not, ouch, it hurts. I didn't touch your side yet. Oh, ok. Does this hurt? Not really. How about this? No, not really. And this ouch, ok. You can sit up. I'm going to refer you to a specialist, a gastroenterologist doctor. \nPerson B: Oh, no. What's wrong with me? \nPerson D: I'm not sure. But it could be something with your gallbladder. However, once you go to the specialist, he will be able to help you further another doctor. Oh, man. \nPerson E: Hi, I'm [NAME]. What's going on, buddy?\n\nSummary: \nPatient [NAME] visited the clinic on a scheduled appointment for a pain in his right side that started about a month ago. He also reported minor pain in his right shoulder. His blood pressure and heart rate were found to be slightly high during the initial examination. The attending doctor, after examining him, suspects a possible issue with his gallbladder and referred him to a gastroenterologist for further diagnosis and treatment."
Since the input audio recording also includes a chorus of other voices, the output might get a tad quirky, as GPT had to channel its inner detective to figure out who’s who and keep their chit-chats from turning into a verbal stew. So, it’s possible that more than just a couple of characters are chiming in this symphonic dialogue. However, the output did manage to whip up a medical record brief from the redacted transcript medley.
Let’s see how it spins out:
Summary:
Patient [NAME] visited the clinic on a scheduled appointment for a pain in his right side that started about a month ago. He also reported minor pain in his right shoulder. His blood pressure and heart rate were found to be slightly high during the initial examination.
The attending doctor, after examining him, suspects a possible issue with his gallbladder and referred him to a gastroenterologist for further diagnosis and treatment."
Do you think this qualifies as a solid medical record brief?
Honestly, I’m not a doctor! It’s probably best to consult a medical professional for their expert opinion. I’m an engineer—I specialize in dealing with inanimate objects that don’t talk back. So, assessing medical documentation isn’t exactly in my wheelhouse. However, the main goal here was to demonstrate how LangChain can effectively redact sensitive information from transcripts and how GPT-4 can be utilized to generate a precise medical record brief.
Conclusion
Congratulations! You’ve successfully streamlined the process of creating medical record briefs while keeping in full compliance with HIPAA regulations. You’ve not only saved time and safeguarded privacy, but you’ve also added a bit of enjoyment to the mix. Who knew compliance could be so exhilarating?
Moreover, this is just a very simple example of how LangChain can be used to redact the sensitive information from the transcription. LangChain can be used in various sectors like healthcare, finance, legal, etc. to redact the sensitive information from the documents.
Note
Ideally everything here should be done in a trusted environment. You don’t want to be leaking sensitive information to the wrong hands, in another way, you don’t want the transcription with sensitive information to be leaked to the wrong hands. Therefore, we need langchain to redact the sensitive information before sharing the transcription with anyone else. In the step before we were assuming that the Transcriber was a trusted environment.
Disclaimer:
This is not a production level code, but just a simple example to show how LangChain can be used to redact the sensitive information from the transcription.